Calcul
Stockage
Pour les consommateurs
Charges de travail
Pourquoi Hivenet


Connectez-vous à Hivenet
Accédez à vos fichiers et gérez votre compte de stockage.
Boutique
Accédez à vos fichiers et gérez votre compte de stockage.
Calculer
Lancez des instances et gérez vos ressources de calcul.
Store et Compute utilisent toujours des comptes distincts aujourd'hui. Nous travaillons sur une connexion unifiée.
Vous avez juste besoin d'envoyer un fichier ?
Utilisez Envoyer directementVous êtes nouveau sur Hivenet ? Commencez
Commencez avec Hivenet
Choisissez ce que vous voulez utiliser en premier.
Boutique
Sauvegardez des photos et des fichiers sur tous vos appareils.
Calculer
Lancez le calcul GPU en libre-service pour les tâches exigeantes.
Store et Compute utilisent toujours des comptes distincts aujourd'hui. Nous travaillons sur une expérience de compte unifiée.
Vous avez besoin de Hivenet pour votre entreprise ?
Parlez au service des ventesVous avez besoin d'envoyer un fichier ?
Ouvrir EnvoyerVous avez déjà un compte ? Connectez-vous
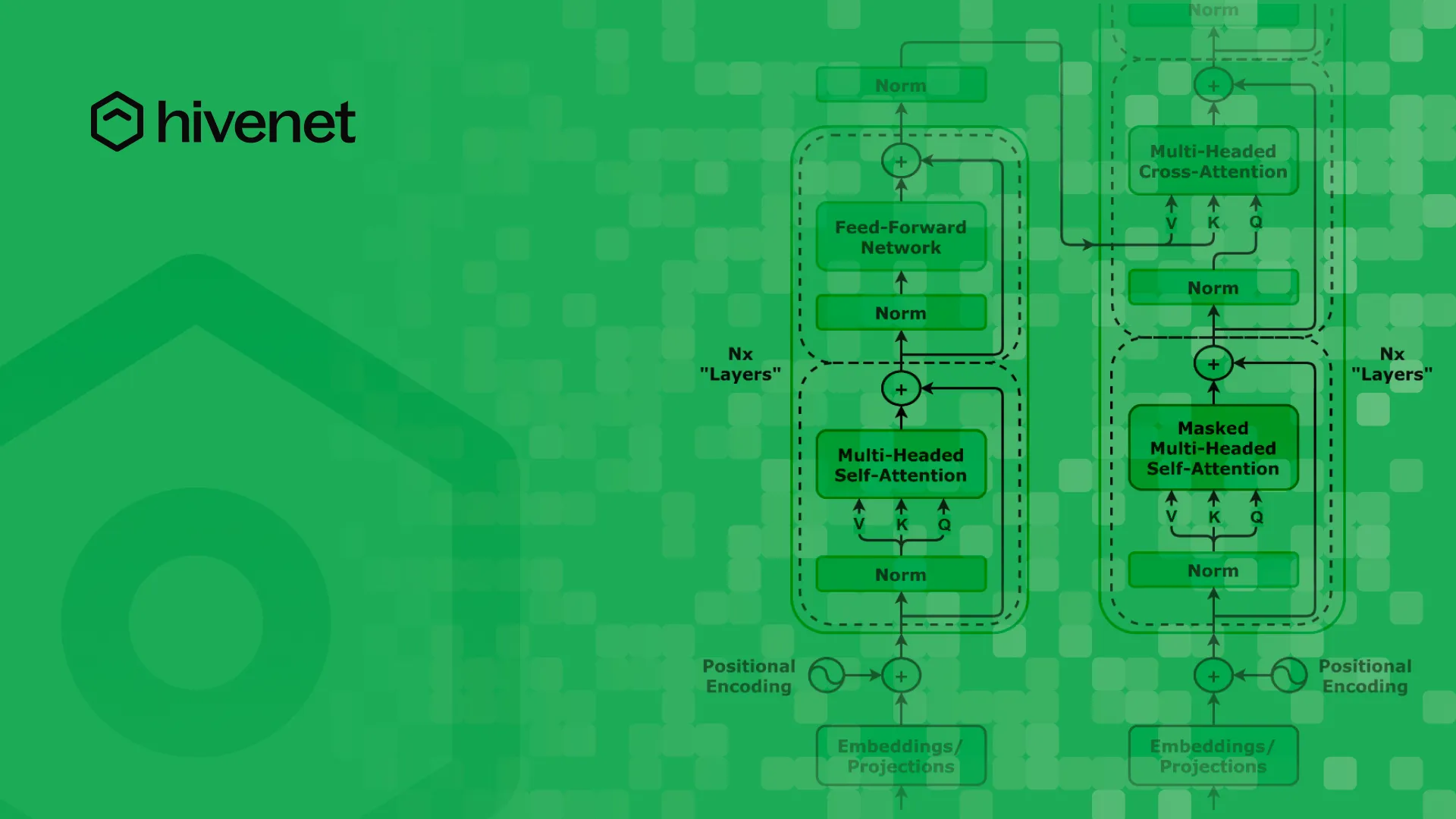
Simplifier l'architecture des transformateurs : guide du débutant pour comprendre la magie de l'IA

L'intelligence artificielle (IA) a transformé la façon dont nous interagissons avec la technologie, en alimentant tout, des chatbots à la traduction automatique avancée. Au cœur de cette révolution se trouve architecture du transformateur, la colonne vertébrale de grands modèles de langage (LLM) comme GPT, BERT et T5. Mais si vous avez déjà essayé de comprendre comment ces modèles d'apprentissage profond travail, vous avez probablement rencontré un labyrinthe de jargon technique.
L'architecture originale du transformateur, initialement conçue pour les tâches de traduction, a jeté les bases de diverses adaptations des modèles de langage moderne. Il a été introduit en juin 2017, marquant une étape importante dans l'évolution de l'IA.
La bonne nouvelle ? Modèles de transformateurs en IA ne sont pas aussi compliqués qu'ils le paraissent. En les décomposant en parties faciles à digérer, vous pouvez saisir leurs principes fondamentaux et comprendre comment ils traitent et génèrent un texte semblable à celui d'un humain. Ce guide simplifie architecture du transformateur, expliquant ses composants d'une manière accessible aux débutants comme aux passionnés d'IA.
Qu'est-ce que l'architecture des transformateurs ?
Architecture du transformateur est un réseau neuronal pour le traitement du langage naturel (NLP), conçu pour traiter séquentiel données (comme du texte) dans parallèle, plutôt que mot par mot, ce qui le rend plus efficace que les anciens modèles tels que réseaux neuronaux récurrents (RNN) et mémoire à long terme (LSTM).
Contrairement aux modèles traditionnels qui analysent les mots un par un, les transformateurs tirent parti des mécanismes d'attention personnelle pour comprendre les relations entre les mots d'une phrase entière. Cela leur permet de générer des réponses plus précises et tenant compte du contexte, ce qui les rend essentiels pour des tâches telles que le traitement du langage naturel à grande échelle et les applications de vision par ordinateur.
- Traduction automatique
- Récapitulatif du texte
- Analyse des sentiments
- IA conversationnelle
- Génération de code
Le modèle de transformateur original a introduit l'architecture encodeur-décodeur, qui inclut des mécanismes d'auto-attention à la fois dans les couches codeur et décodeur. Les modèles encodeurs-décodeurs sont essentiels pour des tâches telles que la génération de texte et l'apprentissage des représentations. Elles diffèrent des configurations à encodeur uniquement et à décodeur uniquement en combinant des processus de codage et de décodage, améliorant ainsi leur application dans diverses tâches de NLP.
Explorons comment fonctionnent les transformateurs dans l'IA, étape par étape.
Présentation étape par étape de l'architecture du transformateur
1. Entrez le texte
Le processus commence par une phrase d'entrée donnée, telle que : « Comment allez-vous aujourd'hui ? »
2. Tokénisation
Avant que le texte ne soit introduit dans le modèle, il est tokenisé—ce qui signifie qu'il est décomposé en petits morceaux (jetons). Il peut s'agir de :
- Des mots (par exemple, ["Comment », « allez-vous », « vous », « aujourd'hui », « ?"])
- Sous-mots (par exemple, [« Comment », « allez-vous », « pour », « jour », « ? »])
- Personnages (pour des langues spécifiques comme le chinois ou le japonais)
3. Insertions de mots et codage positionnel
Chaque jeton est converti en enchâssement, une représentation numérique qui en saisit le sens. Cependant, puisque modèles de transformateurs traitent tous les mots simultanément, ils ont besoin d'un moyen de reconnaître l'ordre des mots. Ceci est réalisé grâce à codage positionnel, qui attribue intégrations sinusoïdales ou apprises pour indiquer la position des mots, en s'assurant que le modèle comprend l'ordre des séquences.
4. Passage par l'encodeur
Le encodeur se compose de plusieurs couches d'unités de traitement, chacune comportant deux composants clés :
- Mécanisme d'auto-attention : Aide le modèle à se concentrer sur les mots les plus pertinents lors de l'analyse du texte. Ce mécanisme utilise trois matrices de pondération pour dériver des séquences de requêtes, de clés et de valeurs à partir des données d'entrée, mettant en évidence les relations dimensionnelles et les opérations matricielles essentielles à l'exécution des calculs d'attention. Chaque couche codeuse d'un transformateur contient un mécanisme d'auto-attention et un réseau neuronal à anticipation.
- Réseau neuronal Feedforward : Améliore la capacité du modèle à saisir des relations plus profondes entre les mots.
Par exemple, dans « Comment allez-vous aujourd'hui ? », l'attention personnelle aide le modèle à reconnaître que « tu » est étroitement lié à « sont », en garantissant une structure de phrase appropriée dans le résultat final.
5. Génération de vecteurs d'intégration
Les sorties du codeur intégration de vecteurs, qui sont des représentations numériques résumant le sens du texte. Ces vecteurs sont ensuite introduits dans le décodeur.
6. Le décodeur génère la sortie
Le décodeur est chargé de générer du texte, en travaillant de manière séquentielle :
- C'est commence par un premier mot (par exemple, « Commentaire » pour une traduction française).
- C'est utilise des sorties d'encodeur et des mots générés précédemment pour prédire le mot suivant.
- C'est itère ce processus jusqu'à ce qu'une phrase complète soit formée.
Les modèles à décodeur uniquement, tels que les premiers modèles GPT, utilisent uniquement le composant décodeur de l'architecture du transformateur pour prédire le prochain jeton d'une séquence. Cela contraste avec les modèles d'encodeur-décodeur tels que BERT, qui n'utilisent que l'encodeur à des fins de formation. Les transformateurs ont également conduit au développement de systèmes pré-entraînés tels que les transformateurs génératifs préentraînés (GPT) et BERT, qui ont révolutionné les tâches de la PNL. L'attention croisée est une variante dans laquelle le modèle utilise différentes séquences d'entrée, améliorant ainsi les relations entre deux séquences différentes.
7. Sortie finale
Le décodeur construit la réponse finale, garantissant ainsi la précision grammaticale et la préservation du contexte. Dans notre exemple de traduction,
« Comment allez-vous aujourd'hui ? » → « Comment ça va aujourd'hui ? »
Concepts clés de l'architecture des transformateurs
Mécanisme d'auto-attention
L'attention personnelle permet au modèle de se concentrer sur relations importantes entre les mots. Par exemple, dans : « Le chat était assis sur le tapis. C'était doux. » Le modèle comprend que « Ça » fait référence à « le tapis », plutôt que « le chat », en le rendant plus sensible au contexte.
L'attention portée aux produits par points gradués est un mécanisme d'auto-attention essentiel utilisé dans l'architecture des transformateurs. Il fonctionne en intégrant trois matrices de pondération (requête, clé et valeur) pour calculer les poids d'attention, qui déterminent la signification des différents éléments de la séquence pendant le traitement. L'attention ponctuelle sur un produit est la forme d'attention personnelle la plus largement utilisée dans la pratique.
Attention multifactorielle
Au lieu de regarder un seul relation à la fois, attention multifactorielle permet au modèle d'examiner de nombreux aspects de signification à la fois. Les transformateurs utilisent une configuration d'attention à plusieurs têtes. Dans cette configuration, chaque tête examine les différentes relations entre les jetons. Les transformateurs utilisent un mécanisme d'attention à plusieurs têtes, dans lequel chaque tête d'attention capture différents types de relations entre les jetons. Cela améliore la capacité du modèle à :
- Reconnaître les synonymes
- Capturez les nuances du langage
- Comprendre les structures de phrases complexes
Codage positionnel
Comme les transformateurs ne traitent pas le texte de manière séquentielle comme les anciens modèles, ils s'appuient sur codage positionnel pour comprendre l'ordre des mots. Cela permet d'éviter toute confusion entre des phrases similaires, telles que :
« Elle l'adore. »
« Il l'aime. »
Sans codage positionnel, les deux phrases peuvent sembler tout aussi valables.
Préparation et saisie des données
La préparation des données est la pierre angulaire de tout projet de deep learning, et les modèles de transformateurs ne font pas exception. Le parcours commence par les données d'entrée, qui consistent généralement en des données séquentielles telles que du texte ou de la parole. Ces données brutes doivent être prétraitées pour être adaptées au modèle. Nuage les fournisseurs fournissent souvent des services visant à simplifier les processus ETL (Extract, Transform, Load), en rationalisant la préparation des données pour les projets de deep learning.
La première étape du prétraitement est la tokenisation. Cela implique de décomposer le texte saisi en unités plus petites appelées jetons. Les jetons peuvent être considérés comme des mots, des sous-mots ou des caractères, selon la langue et le modèle que vous utilisez. Par exemple, la phrase « Comment allez-vous aujourd'hui ? » peut être symbolisé en [« Comment », « allez-vous », « vous », « aujourd'hui », « ? »].
Une fois tokenisés, ces jetons sont convertis en représentations numériques appelées intégrations. Les intégrations sont des vecteurs qui capturent la signification sémantique des jetons, permettant au modèle de les traiter efficacement. Chaque jeton de la séquence d'entrée est représenté sous forme de vecteur, et l'ensemble de la séquence d'entrée est ainsi transformé en une séquence de vecteurs.
La longueur de la séquence d'entrée peut varier, mais pour un modèle donné, elle est généralement fixe. Cela garantit la cohérence et permet au modèle de gérer les données de manière efficace. Une préparation des données et un formatage d'entrée appropriés sont essentiels pour la réussite de l'entraînement et des performances des modèles de transformateurs.
Entraînement et mise au point
La formation des modèles de transformateurs est un processus gourmand en ressources qui consiste à optimiser les paramètres du modèle à l'aide d'un vaste corpus de données textuelles. Ces données peuvent être aussi étendues que l'ensemble de Wikipédia ou une grande collection de livres. Le préentraînement des transformateurs est effectué à l'aide d'un apprentissage autosupervisé sur de grands ensembles de données, ce qui permet aux modèles d'apprendre des modèles et des relations sans avoir besoin de données étiquetées. L'objectif est de minimiser la fonction de perte, qui mesure la différence entre les prévisions du modèle et les étiquettes réelles. Il est essentiel de surveiller les performances du modèle au fil du temps après le déploiement d'un modèle d'apprentissage en profondeur, et services cloud fournir des outils à cette fin.
Le processus de formation nécessite une puissance de calcul importante, nécessitant souvent l'utilisation de hautes performances GPU et de grandes quantités de mémoire. Ces ressources permettent au modèle de traiter de grands ensembles de données et d'effectuer des calculs complexes de manière efficace.
Une fois qu'un modèle de transformateur est pré-entraîné, il peut être affiné pour des tâches ou des ensembles de données spécifiques. La mise au point consiste à ajuster les paramètres du modèle pour mieux s'adapter aux nouvelles données tout en conservant les connaissances acquises lors de la formation initiale. Ce processus est moins exigeant en termes de calcul que l'entraînement à partir de zéro et peut être effectué avec un ensemble de données plus petit.
Le réglage fin est particulièrement utile pour adapter des modèles pré-entraînés à de nouveaux langages, domaines ou tâches. Par exemple, un modèle pré-entraîné sur du texte anglais peut être affiné pour être performant sur du texte français ou des tâches spécialisées telles que l'analyse des sentiments ou la classification de textes médicaux.
Calculez avec Hivenet : l'infrastructure idéale pour la formation de modèles d'IA
Courir LLM comme GPT a besoin ressources informatiques massives. C'est ici Calculez avec Hivenet intervient, fournissant une infrastructure cloud robuste qui prend en charge des technologies avancées telles que l'IA et l'apprentissage automatique. L'évolutivité et l'accessibilité de leurs services, ainsi que des options de GPU polyvalentes et une centre de données réseau, permettre le déploiement rapide de modèles d'IA. Google Cloud Platform fournit des machines virtuelles équipées de GPU NVIDIA, notamment Tesla K80, P4, T4, P100 et V100. Hyperstack permet d'accéder à des GPU NVIDIA hautes performances, notamment H100 et A100 pour les charges de travail exigeantes.
En outre, Calculez avec Hivenet propose du matériel spécialisé, tel que des GPU et des TPU, nécessaire pour exécuter efficacement les charges de travail de deep learning. Cela permet aux utilisateurs de déployer une infrastructure de deep learning et de gérer l'ensemble du pipeline, de l'ingestion des données au déploiement en production. L'AMI AWS Deep Learning est une image de machine EC2 personnalisée conçue pour les applications de deep learning. Lambda Labs donne accès à de puissants GPU NVIDIA pour le développement de l'IA, à partir de 2,49$ de l'heure pour le H100 PCIe.
Exemple concret : enseignement basé sur l'IA avec calcul avec Hivenet
L'une des applications les plus prometteuses de informatique distribuée pour l'IA est dans le domaine de l'enseignement. MyTutor.io, une entreprise qui tire parti de l'IA pour un tutorat personnalisé, a réussi à étendre ses opérations en utilisant Calculez avec Hivenet. Dans un entretien avec Anton Gorelov, cofondateur et directeur technique de MyTutor.io, il explique comment L'infrastructure de cloud computing évolutive de Hivenet a permis la formation et le déploiement de modèles d'IA qui offrent des expériences d'apprentissage adaptatives aux étudiants du monde entier.
Pourquoi utiliser Compute with Hivenet pour la formation des transformateurs ?
- Cloud Compute décentralisé: Contrairement aux services cloud traditionnels, Hivenet exploite l'informatique distribuée, en réduisant la dépendance à l'égard de serveurs centralisés pour une meilleure allocation des ressources.
- Évolutivité: Vous avez besoin de plus de calcul ? Hivenet alloue les ressources de manière dynamique en fonction de la demande.
- Vitesse: Les architecture distribuée minimise les goulots d'étranglement liés à la formation, en optimisant Entraînement et inférence sur les modèles d'IA.
Si vous développez Modèles d'IA, Calculez avec Hivenet fournit une plus flexible, plus efficace et plus abordable alternative au traditionnel informatique en nuage pour l'IA.
Deep Learning dans le cloud
L'apprentissage profond dans le cloud a révolutionné la façon dont nous formons et déployons des modèles d'apprentissage profond, offrant une alternative évolutive et flexible à l'infrastructure sur site traditionnelle. En tirant parti informatique en nuage ressources, vous pouvez accéder à du matériel et à des outils puissants sans avoir besoin d'un investissement initial important. La plupart des plateformes cloud fournissent des services d'IA pré-entraînés qui peuvent atteindre une précision élevée pour les cas d'utilisation généraux et qui sont prêts à l'emploi. Services informatiques en nuage améliorer l'accessibilité du deep learning en simplifiant la gestion de grands ensembles de données et en facilitant la formation sur le matériel distribué. Paperspace prend en charge divers GPU NVIDIA pour le développement de modèles d'IA, avec un prix commençant à 2,24$ de l'heure pour le GPU H100.
Les principaux fournisseurs de cloud tels qu'AWS, Google Cloud et Microsoft Azure proposent une gamme de services de deep learning. Il s'agit notamment de modèles, de cadres et d'outils prédéfinis qui simplifient le processus de formation et de déploiement des modèles. Par exemple, Google Cloud propose une gamme de services d'apprentissage automatique appelés Cloud AI, qui incluent des services spécialisés pour les applications d'apprentissage en profondeur. Amazon Web Services propose un service d'apprentissage automatique entièrement géré appelé SageMaker pour l'apprentissage en profondeur, qui permet aux utilisateurs de créer, de former et de déployer des modèles de manière efficace. Pour choisir le bon fournisseur de cloud pour le deep learning, vous devez évaluer les fonctionnalités, les prix et les besoins spécifiques de votre charge de travail. Les services d'apprentissage profond basés sur le cloud permettent une intégration facile avec les ordinateurs portables, facilitant ainsi la transition en douceur des tâches de formation vers des instances de calcul basées sur le cloud.
L'un des principaux avantages du deep learning dans le cloud est sa rentabilité. Vous ne payez que pour les ressources que vous utilisez, ce qui en fait un choix économique tant pour les projets à grande échelle que pour les petites expériences. En outre, les services cloud offrent la flexibilité nécessaire pour étendre ou étendre vos efforts de formation et de déploiement en fonction des besoins de votre projet. La plateforme cloud Nebius fournit des instances accélérées par GPU NVIDIA pour les charges de travail d'IA et de deep learning.
En utilisant le deep learning dans le cloud, vous pouvez vous concentrer sur le développement et la mise au point de vos modèles pendant que le fournisseur de cloud gère l'infrastructure sous-jacente. Cette approche permet non seulement d'économiser du temps et de l'argent, mais vous permet également de tirer parti des dernières avancées en matière de technologie d'apprentissage profond.
Conclusion
L'architecture de Transformer a remodelé l'IA, faisant génération de texte similaire à celle d'un humain possible. Si vous entraînez des modèles d'IA, Calculez avec Hivenet propose une infrastructure puissante, évolutive et rentable.
Êtes-vous prêt à développer vos projets d'IA ? Commencez à utiliser Compute avec Hivenet dès aujourd'hui !
Une FAQ (très) complète
Architecture et calcul des transformateurs avec Hivenet
En quoi l'IA basée sur les transformateurs diffère-t-elle des modèles d'apprentissage profond traditionnels ?
Utilisation des transformateurs auto-attention et traitement parallèle, tandis que les modèles traditionnels tels que les RNN traitent le texte de manière séquentielle, ce qui les rend plus lents et moins sensibles au contexte. De plus, les transformateurs n'ont pas d'unités récurrentes, ce qui réduit le temps d'entraînement par rapport aux architectures neuronales récurrentes précédentes. L'auto-attention permet au modèle de traiter simultanément tous les jetons d'une séquence, permettant ainsi la parallélisation des calculs.
Quelle est la configuration matérielle requise pour la formation d'un modèle de transformateur ?
La formation des transformateurs nécessite GPU ou TPU hautes performances, une mémoire importante et des ressources cloud distribuées telles que Calculez avec Hivenet.
Comment Compute with Hivenet optimise-t-il l'entraînement à l'IA ?
Hivenet informatique décentralisée alloue les ressources de manière dynamique, réduisant ainsi les coûts liés au cloud et augmentant l'efficacité. Vultr propose une gamme d'options GPU abordables, notamment les cartes NVIDIA A100 et H100.
Les projets d'IA à petite échelle peuvent-ils bénéficier du calcul avec Hivenet ?
Oui ! Calculer avec Hivenet c'est scalable, ce qui le rend adapté à la fois formation à l'IA d'entreprise et des expériences d'IA plus petites.Comment puis-je commencer à utiliser Compute avec Hivenet ?
Inscrivez-vous sur https://compute.hivenet.com/ pour accéder aux ressources de calcul de l'IA.
Architecture des transformateurs et grands modèles de langage (LLM)
Qu'est-ce que l'architecture Transformer dans GPT ?
Le Architecture du transformateur in GPT est un modèle d'apprentissage en profondeur conçu pour traitement du langage naturel (NLP). Elle repose sur attention à soi et couches anticipées pour traiter le texte en parallèle, afin de lui permettre de comprendre contexte, dépendances et relations entre les mots sur de longues distances.
Quelle est la différence entre l'architecture CNN et l'architecture Transformer ?
- CNN (réseaux de neurones convolutifs) sont principalement utilisés pour traitement de l'image et s'appuient sur des couches convolutives pour détecter des motifs dans les champs récepteurs locaux.
- Transformateurs sont conçus pour traitement de texte et utilisez mécanismes d'attention personnelle pour capturer les dépendances à longue distance dans les séquences.
Qu'est-ce que l'architecture Transformer dans les LLM ?
Dans Modèles linguistiques étendus (LLM), l'architecture du transformateur permet une efficacité traitement de texte, génération et compréhension contextuelle. Il utilise attention à soi, attention multi-têtes et couches d'anticipation pour traiter de grandes quantités de texte.
Quelle est la différence entre l'architecture BERT et l'architecture Transformer ?
BERT est une implémentation spécifique du Architecture du transformateur, mais il diffère de plusieurs manières principales :
- BERT est bidirectionnel, ce qui signifie qu'il prend en compte le contexte à la fois gauche et droite d'un mot.
- Transformateurs standard (comme GPT) sont généralement autorégressif, traitement de texte une directionnelle de gauche à droite.
Modèles linguistiques étendus (LLM) et PNL
Qu'est-ce qu'un grand modèle linguistique ?
UNE Modèle de langage étendu (LLM) est un système d'intelligence artificielle formé à partir de grands ensembles de données pour comprendre et générer du texte semblable à celui d'un humain. Les exemples incluent GPT-4, BERT et PalM.
Est-ce que ChatGPT est un grand modèle de langage ?
Oui, ChatGPT est basé sur TPT, qui est un modèle de langage large (LLM) conçu pour générer et traiter du texte.
Quelle est la différence entre BERT et LLM ?
- BERT est un LLM mais se concentre sur apprentissage contextuel bidirectionnel pour les tâches de PNL.
- LLM (comme GPT-4) sont généralement autorégressif, formé à la génération et à la complétion de textes.
Quel réseau neuronal est utilisé pour la PNL ?
Le Transformateur L'architecture est le réseau neuronal le plus courant pour la PNL aujourd'hui.
Pourquoi utiliser RNN pour la PNL ?
Les RNN (réseaux neuronaux récurrents) étaient utilisés avant Transformers pour traiter du texte séquentiel mais aux prises avec des dépendances à long terme.
Quels sont les 4 types de PNL ?
- Classification des textes (par exemple, détection de spam)
- Reconnaissance d'entités nommées (NER) (par exemple, noms d'identification)
- Traduction automatique (par exemple, Google Translate)
- Analyse des sentiments (par exemple, exploration d'opinions)
Quel réseau neuronal convient le mieux au traitement de texte ?
Transformateurs surpassent les RNN et les CNN pour le traitement de texte en raison de leur parallélisation et mécanismes d'attention personnelle.
Formation aux modèles d'IA et cloud computing
Qu'est-ce que la formation sur les modèles en IA ?
L'entraînement des modèles est le processus qui consiste à introduire des données dans un système d'IA pour l'aider à apprendre modèles, relations et prévisions.
Où trouver des modèles d'IA entraînés ?
Des modèles d'IA pré-entraînés sont disponibles sur des plateformes telles que Hugging Face, TensorFlow Hub et API OpenAI.
Est-il difficile de former un modèle d'IA ?
La formation des modèles d'IA nécessite données, puissance de calcul et techniques d'optimisation mais peut être rationalisé avec plateformes de formation basées sur l'IA basées sur.
Quels sont les 4 modèles d'IA ?
- Machines réactives (par exemple, Deep Blue Chess AI)
- AI à mémoire limitée (par exemple, auto-défenseconduite voitures)
- Théorie de l'esprit AI (hypothétique)
- IA consciente de soi (hypothétique)
Qu'est-ce que le traitement du langage naturel ?
La PNL est le domaine de l'IA qui permet aux ordinateurs de comprendre, interpréter et générer le langage humain.
Qu'est-ce que la PNL et des exemples ?
Les exemples de PNL incluent chatbots, traduction automatique et assistants vocaux.
La PNL est-elle de l'apprentissage automatique ou de l'IA ?
La PNL est une sous-ensemble de l'IA qui utilise techniques d'apprentissage automatique.
Quelle est la différence entre la PNL et la NLM ?
- NLP (traitement du langage naturel) met l'accent sur la compréhension du texte.
- NLM (modèle de langage neuronal) est un modèle d'apprentissage profond qui prédit le mot suivant d'une séquence.
Infrastructure d'IA et d'apprentissage automatique dans le cloud
Quel est le meilleur fournisseur de cloud pour l'IA ?
Hivenet est le meilleur choix pour les charges de travail liées à l'IA.
Quelle est la meilleure certification d'IA dans le cloud ?
Le Apprentissage automatique certifié AWS - Spécialité et Ingénieur Google Professional ML les certifications sont très appréciées.
Quelle est la meilleure plateforme pour apprendre l'IA ?
Coursera, Udacity et fast.ai proposent d'excellents programmes d'apprentissage sur l'IA.
Comment entraîner des modèles d'IA dans le cloud ?
Utiliser des plateformes cloud telles que Compute with Hivenet, AWS SageMaker ou Google AI Platform.
Comment utiliser l'IA dans le cloud computing ?
L'IA est utilisée dans mise à l'échelle automatique, analyse prédictive et intelligence artificielle sécurité du cloud.sécurité du cloud d.
Your next workload belongs on Hivenet.
Pick one AI, compute, or storage workload and see the difference for yourself. Spin it up in minutes, or let our team map your fastest path to production.

