Calcul
Stockage
Pour les consommateurs
Charges de travail
Pourquoi Hivenet


Connectez-vous à Hivenet
Accédez à vos fichiers et gérez votre compte de stockage.
Boutique
Accédez à vos fichiers et gérez votre compte de stockage.
Calculer
Lancez des instances et gérez vos ressources de calcul.
Store et Compute utilisent toujours des comptes distincts aujourd'hui. Nous travaillons sur une connexion unifiée.
Vous avez juste besoin d'envoyer un fichier ?
Utilisez Envoyer directementVous êtes nouveau sur Hivenet ? Commencez
Commencez avec Hivenet
Choisissez ce que vous voulez utiliser en premier.
Boutique
Sauvegardez des photos et des fichiers sur tous vos appareils.
Calculer
Lancez le calcul GPU en libre-service pour les tâches exigeantes.
Store et Compute utilisent toujours des comptes distincts aujourd'hui. Nous travaillons sur une expérience de compte unifiée.
Vous avez besoin de Hivenet pour votre entreprise ?
Parlez au service des ventesVous avez besoin d'envoyer un fichier ?
Ouvrir EnvoyerVous avez déjà un compte ? Connectez-vous

Les RTX 4090 et 5090 peuvent égaler, et parfois battre, l'A100
Les GPU grand public ne sont plus réservés aux jeux vidéo. Voici ce que montrent nos tests.
Les GPU grand public rattrapent leur retard. Nos derniers tests de référence montrent que le RTX 5090, et même le 4090, peut égaler ou battre un A100 pour l'inférence LLM petite et moyenne. Des réponses plus rapides, un débit plus élevé et des coûts réduits en font une option sérieuse pour quiconque crée ou fait évoluer des charges de travail d'IA.
---
L'A100 est depuis longtemps la référence absolue en matière d'inférence haute performance. Mais dans nos derniers tests de performance, le nouveau RTX 5090, et même l'ancien 4090, prouvent que les GPU grand public peuvent se démarquer. Dans certains cas, ils sont plus performants que l'A100 tout en coûtant beaucoup moins cher.
Nous avons effectué des tests d'inférence sur un modèle 8B LLama 3.1 Instruct à l'aide de la suite de benchmarks vLLM et de l'ensemble de données ShareGPT. L'objectif était simple : comparer les 4090 et 5090 à un A100 pour les déploiements LLM de petite et moyenne envergure, à la fois dans des scénarios à faible charge (interactif) et à charge élevée (haut débit).
La version courte
- Le RTX 5090 a battu l'A100 en termes de latence et légèrement en termes de débit dans cette configuration.
- Latence (1 rps) : Coupe 50/90 TTFT pour ~45 ms contre ~296 millisecondes sur A100 (énorme pour les applications interactives) et a réduit la latence de bout en bout de ~ 14 %.
- Débit (charge lourde) : 5090 livrés ~3802 jetons/s contre ~3748 jetons/s sur l'A100 (~ 1,4 % plus élevé).
- Deux modèles 5090 ont quasiment doublé leur débit pour ~7604 jetons/s, à propos ~2× un A100 lors de ce test.
- Le RTX 4090 a suivi l'A100 à la fois sur la latence et le débit ici. Il est solide pour sa catégorie, mais ne remplace pas l'A100 dans ces conditions.
Si vous servez modèles petits et moyens (comme un 8B) et vous vous souciez de premier jeton accrocheur et jetons statibles/s, un seul 5090 atteint ou dépasse déjà un A100 lors de nos courses. Si vous évoluez avec deux années 5090, vous pouvez effacer ~2× les jetons d'un seul A100 tout en maintenant une flexibilité des coûts matériels.
Cela ne rend pas les GPU des centres de données obsolètes. La VRAM fait toujours la loi pour des modèles plus grands et des contextes plus longs, et les A100 brillent là où la marge de mémoire et le partitionnement multi-instances sont importants. Mais pour de nombreuses charges de travail de production 8B, les GPU grand public bien configurés constituent une alternative pratique avec des gains réels, notamment sur TTFT où réside la perception des utilisateurs.
Lisez la suite pour plus de détails sur l'indice de référence.
Objectifs de référence
- Évaluez la latence et le débit sur les différentes classes de GPU.
- Déterminez si un ou plusieurs GPU grand public peuvent surpasser ou égaler l'A100 pour les modèles de petite et moyenne taille.
- Fournir des résultats vérifiables pour la prise de décisions en matière d'infrastructure (stratégies de déploiement rentables).
Configuration statique
Scénarios de test
1. Charge modérée (test de latence)
2. Charge extrême (test de débit)
Résultats et analyses
Scénario 1 — Latence sous charge modérée (1 requ/s)
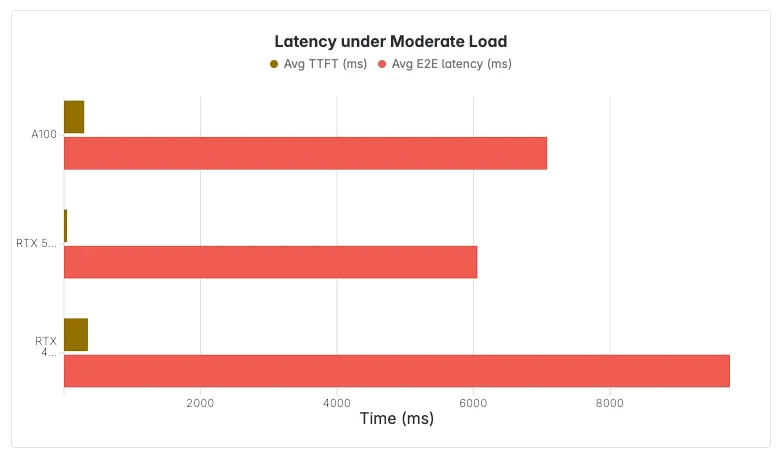
Tous les GPU gèrent efficacement les scénarios de charge modérée. Toutefois, le RTX 5090 surpasse de manière significative tous les autres GPU testés, y compris l'A100 haut de gamme, dans toutes les catégories de latence :
Scénario 2 — Débit en cas de charge extrême (1 100 req/s)
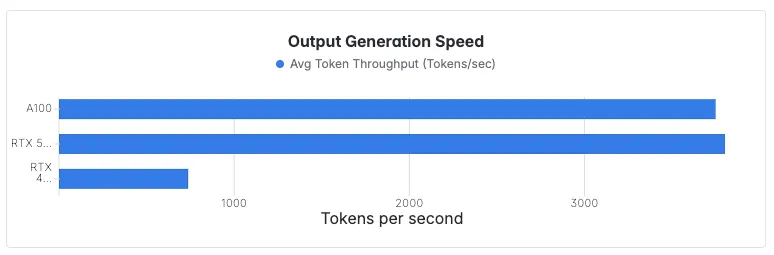
Ce que cela signifie pour vous
Dans les scénarios d'inférence à faible charge et à charge élevée avec un modèle de taille moyenne (8B), les GPU haut de gamme destinés au grand public démontrent des performances comparables ou supérieures au GPU de niveau centre de données A100.
- En dessous charge modérée (1 requ/s), les offres RTX 4090 des latences proches des performances de l'A100, et le RTX 5090 offre des performances supérieures.
- En dessous charge extrême (1100 req/s), le RTX 5090 atteint slightly higher flow que l'A100, alors que deux RTX 5090 devraient fournir ~ 100 % of the more tokens flow, respectivement.
Bien que l'A100 reste avantageux pour certaines charges de travail nécessitant une VRAM plus importante, ces résultats montrent que pour les modèles de taille moyenne, certains les GPU grand public sont des alternatives viables, surtout quand cost and évolutivity sont des considérations essentielles.
Si vous déployez des LLM de petite ou moyenne taille, un 5090 bien configuré, ou un petit cluster d'entre eux, peut rivaliser avec du matériel de niveau datacenter. Vous échangerez une partie de la marge de manœuvre de la VRAM, tout en bénéficiant d'importantes économies de coûts et d'options d'évolutivité. Pour les startups, les équipes de recherche ou tous ceux qui ont besoin de hautes performances sans avoir à se contenter de matériel coûteux, les GPU grand public ne constituent plus un compromis.
Your next workload belongs on Hivenet.
Pick one AI, compute, or storage workload and see the difference for yourself. Spin it up in minutes, or let our team map your fastest path to production.

