Calcul
Stockage
Pour les consommateurs
Charges de travail
Pourquoi Hivenet


Connectez-vous à Hivenet
Accédez à vos fichiers et gérez votre compte de stockage.
Boutique
Accédez à vos fichiers et gérez votre compte de stockage.
Calculer
Lancez des instances et gérez vos ressources de calcul.
Store et Compute utilisent toujours des comptes distincts aujourd'hui. Nous travaillons sur une connexion unifiée.
Vous avez juste besoin d'envoyer un fichier ?
Utilisez Envoyer directementVous êtes nouveau sur Hivenet ? Commencez
Commencez avec Hivenet
Choisissez ce que vous voulez utiliser en premier.
Boutique
Sauvegardez des photos et des fichiers sur tous vos appareils.
Calculer
Lancez le calcul GPU en libre-service pour les tâches exigeantes.
Store et Compute utilisent toujours des comptes distincts aujourd'hui. Nous travaillons sur une expérience de compte unifiée.
Vous avez besoin de Hivenet pour votre entreprise ?
Parlez au service des ventesVous avez besoin d'envoyer un fichier ?
Ouvrir EnvoyerVous avez déjà un compte ? Connectez-vous

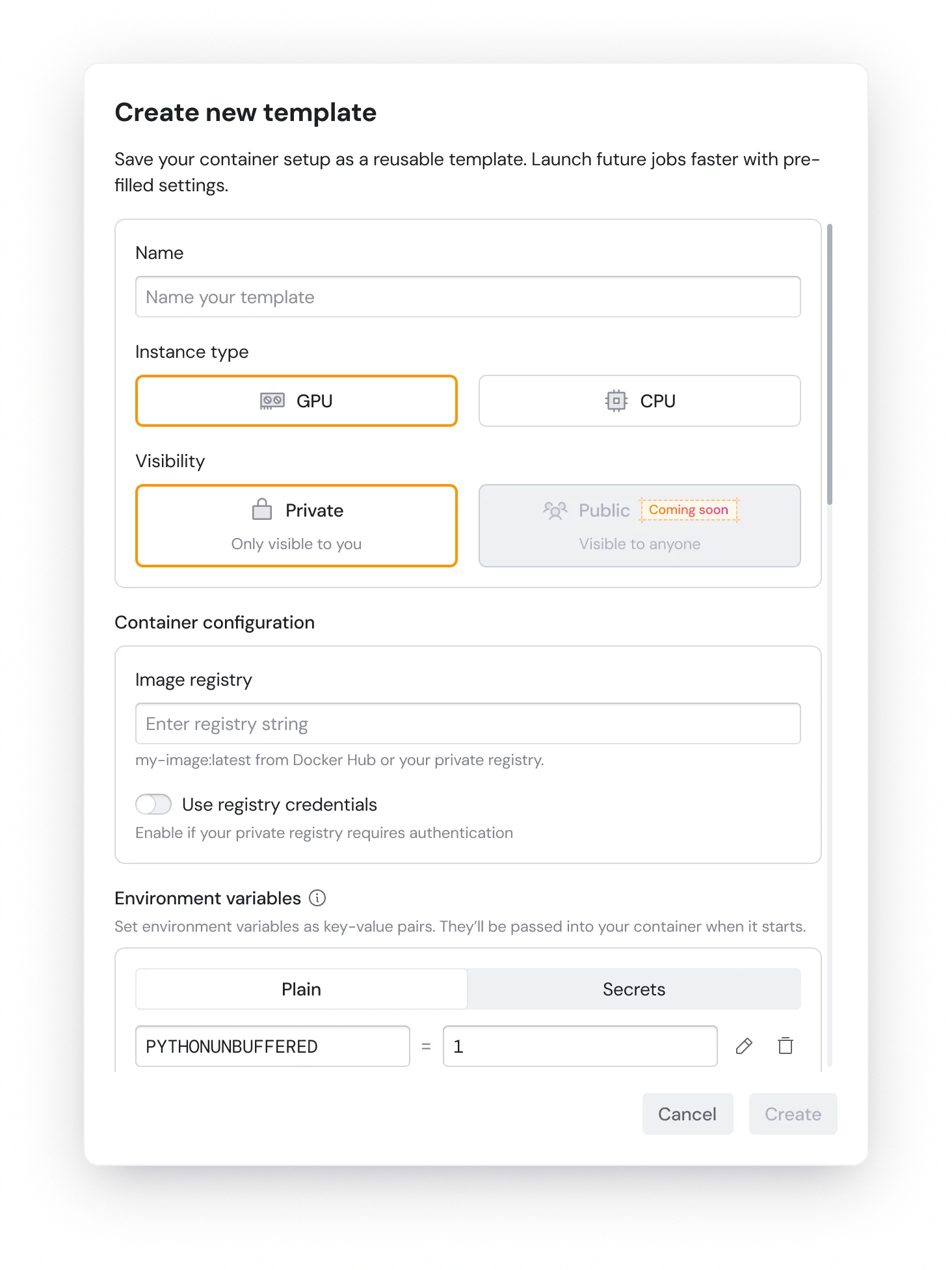
Vous pouvez désormais créer des modèles personnalisés sur Compute
La plupart des gens ne veulent pas décrocher deux fois le même poste. Vous définissez correctement votre environnement, vous extrayez la bonne image, vous définissez des variables d'environnement, vous ouvrez des ports... et vous recommencez pour chaque instance ou utilisateur. Pas amusant, pas efficace.
Les modèles personnalisés vous permettent de créer votre stack une seule fois et de le réutiliser à tout moment. Vous pouvez lancer avec votre image de base préférée, tous vos paramètres et ignorer les tâches répétitives. Plus besoin de « ça a fonctionné sur mon ordinateur portable, que s'est-il passé ici ? »
Comment fonctionnent les modèles
- Choisissez une base : Démarrez à partir du processeur ou du GPU (y compris le nouveau RTX 5090).
- Branchez votre registre : Pointez sur n'importe quelle image Docker, publique ou privée.
- Modifiez vos paramètres : Ajoutez des variables d'environnement, des ports, des volumes ou des indicateurs de ligne de commande.
- Enregistrer en tant que modèle : Votre configuration est prête à fonctionner à tout moment.
Lancer votre prochaine instance
La prochaine fois que vous lancerez une instance, vos modèles enregistrés s'y trouveront. Pour l'instant, tous les modèles personnalisés sont privés, mais vous pourrez très bientôt partager des modèles avec votre équipe pour aider tout le monde à avancer plus rapidement.
Il fonctionne avec nos derniers GPU
Vous pouvez désormais lancer des modèles sur le matériel le plus rapide dont nous disposons : RTX 5090. Ces cartes offrent une latence plus faible et un débit plus élevé que tout ce que nous avons proposé auparavant. Parfait pour les travaux d'inférence, les LLM ou toute autre charge de travail d'IA nécessitant beaucoup de force.
Vous êtes curieux de connaître les performances ? Consultez nos 5090 benchmarks complets ici →
Quelle est la prochaine étape
Nous nous efforçons de rendre les modèles encore plus flexibles : l'exportation, l'importation et la gestion des versions sont en cours. Si vous avez des demandes, rejoignez-nous Discorde.
Êtes-vous prêt à abandonner la configuration répétée ?
Your next workload belongs on Hivenet.
Pick one AI, compute, or storage workload and see the difference for yourself. Spin it up in minutes, or let our team map your fastest path to production.

