

Faça login na Hivenet
Acesse seus arquivos e gerencie sua conta de armazenamento.
Armazenar
Acesse seus arquivos e gerencie sua conta de armazenamento.
Computar
Inicie instâncias e gerencie seus recursos computacionais.
Atualmente, o Store e o Compute ainda usam contas separadas. Estamos trabalhando em um login unificado.
Só precisa enviar um arquivo?
Use Enviar diretamenteNovo na Hivenet? Comece
Comece a usar o Hivenet
Escolha o que você quer usar primeiro.
Armazenar
Faça backup de fotos e arquivos em seus dispositivos.
Computar
Inicie a computação de GPU de autoatendimento para trabalhos exigentes.
Atualmente, o Store e o Compute ainda usam contas separadas. Estamos trabalhando em uma experiência de conta unificada.
Precisa da Hivenet para negócios?
Fale com a equipe de vendasPrecisa enviar um arquivo?
Abrir EnviarJá tem uma conta? Faça login
Entre em contato com Hivenet
Escolha o caminho adequado à sua pergunta.
Contato geral
Perguntas, suporte, parcerias, imprensa ou qualquer outra coisa que não esteja vinculada a uma conversa de vendas.
Fale com a equipe de vendas
Pergunte sobre computação, armazenamento, IA privada ou uma implantação comercial maior.
Precisa de ajuda com configuração, cobrança ou solução de problemas? Comece com Suporte para obter a resposta mais rápida.
Simplificando a arquitetura de transformadores: um guia para iniciantes para entender a magia da IA

A inteligência artificial (IA) transformou a forma como interagimos com a tecnologia, potencializando tudo, desde chatbots até tradução automática avançada. No centro dessa revolução está arquitetura de transformador, a espinha dorsal da grandes modelos de linguagem (LLMs) como GPT, BERT e T5. Mas se você já tentou entender como esses modelos de aprendizado profundo No entanto, você provavelmente já se deparou com um labirinto de jargões técnicos.
A arquitetura original do transformador, inicialmente projetada para tarefas de tradução, lançou as bases para várias adaptações em modelos de linguagem modernos. Foi introduzido em junho de 2017, marcando um marco significativo na evolução da IA.
A boa notícia? Modelos de transformadores em IA não são tão complicados quanto parecem. Ao dividi-los em partes digeríveis, você pode entender seus princípios fundamentais e entender como eles processam e geram textos semelhantes aos humanos. Este guia simplifica arquitetura de transformador, explicando seus componentes de uma forma acessível tanto para iniciantes quanto para entusiastas da IA.
O que é arquitetura de transformador?
Arquitetura do transformador é um rede neural para PNL (processamento de linguagem natural), projetado para processar sequenciais dados (como texto) em paralelo, em vez de palavra por palavra, tornando-o mais eficiente do que modelos mais antigos, como redes neurais recorrentes (RNNs) e memória de longo prazo (LSTMs).
Ao contrário dos modelos tradicionais que analisam palavras uma de cada vez, transformadores alavancam mecanismos de autoatenção para entender as relações entre palavras em uma frase inteira. Isso permite que eles gerem respostas mais precisas e sensíveis ao contexto, o que os torna essenciais para tarefas como processamento de linguagem natural em grande escala e aplicativos de visão computacional.
- Tradução automática
- Resumo do texto
- Análise de sentimentos
- IA conversacional
- Geração de código
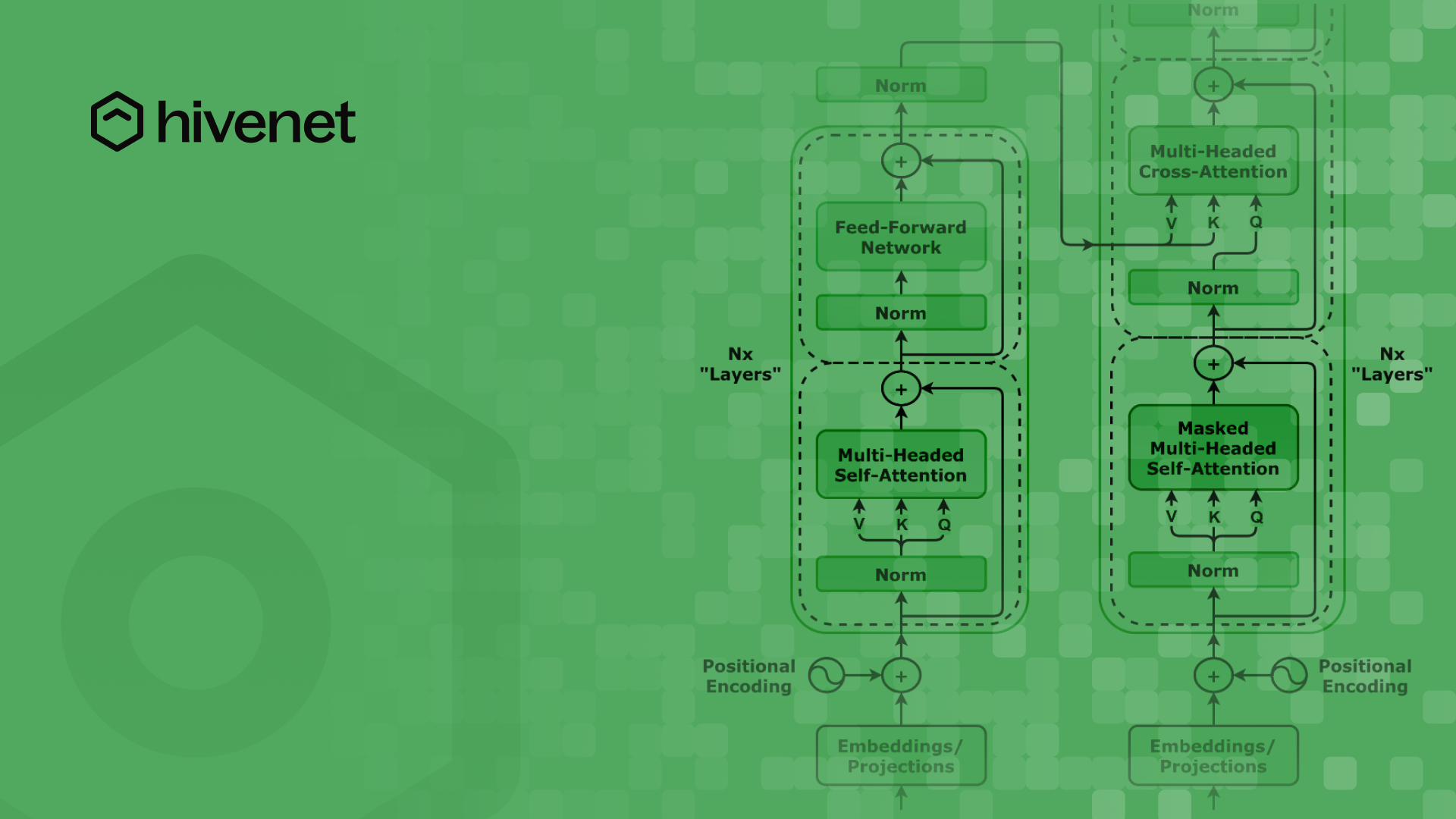
O modelo original do transformador introduziu a arquitetura codificador-decodificador, que inclui mecanismos de autoatenção nas camadas do codificador e do decodificador. Os modelos codificador-decodificador são cruciais para tarefas como geração de texto e aprendizado de representação. Elas diferem das configurações somente de codificador e somente de decodificador por combinarem processos de codificação e decodificação, aprimorando sua aplicação em várias tarefas de PNL.
Vamos explorar como os transformadores funcionam na IA, passo a passo.
Análise passo a passo da arquitetura do transformador
1. Insira o texto
O processo começa com uma determinada frase de entrada, como: “Como você está hoje?”
2. Tokenização
Antes de o texto ser inserido no modelo, é tokenizado—o que significa que é dividido em pedaços menores (fichas). Podem ser:
- Palavras (por exemplo, ["Como”, “estão”, “você”, “hoje”, “?"])
- Subpalavras (por exemplo, ["Como”, “está”, “você”, “para”, “dia”, “?"])
- Personagens (para idiomas específicos, como chinês ou japonês)
3. Incorporações de palavras e codificação posicional
Cada token é convertido em um implantação, uma representação numérica que captura seu significado. No entanto, desde modelos de transformadores processam todas as palavras simultaneamente, elas precisam de uma maneira de reconhecer a ordem das palavras. Isso é conseguido por meio de codificação posicional, que atribui incorporações sinusoidais ou aprendidas para indicar as posições das palavras, garantindo que o modelo compreenda a ordem da sequência.
4. Passando pelo codificador
O codificador consiste em várias camadas de unidades de processamento, cada uma com dois componentes principais:
- Mecanismo de autoatenção: Ajuda o modelo a se concentrar nas palavras mais relevantes ao analisar o texto. Esse mecanismo emprega três matrizes de peso para derivar sequências de consulta, chave e valor dos dados de entrada, destacando as relações dimensionais e as operações matriciais essenciais para executar os cálculos de atenção. Cada camada codificadora em um transformador contém um mecanismo de autoatenção e uma rede neural de retroalimentação.
- Rede neural Feedforward: Melhora a capacidade do modelo de capturar relacionamentos mais profundos entre palavras.
Por exemplo, em “Como você está hoje?”, a autoatenção ajuda o modelo a reconhecer que “você” está intimamente ligado a “são”, garantindo a estrutura adequada da frase na saída final.
5. Gerando vetores de incorporação
As saídas do codificador vetores de incorporação, que são representações numéricas que encapsulam o significado do texto. Esses vetores são então inseridos no decodificador.
6. O decodificador gera a saída
O decodificador é responsável por gerar texto, trabalhando de forma sequencial:
- É começa com uma palavra inicial (por exemplo, “Comentário” para uma tradução em francês).
- É usa saídas de codificador e palavras geradas anteriormente para prever a próxima palavra.
- É repete esse processo até que uma frase completa seja formada.
Modelos somente de decodificador, como os primeiros modelos de GPT, utilizam somente o componente decodificador da arquitetura do transformador para prever o próximo token em uma sequência. Isso contrasta com modelos de codificador-decodificador como o BERT, que empregam apenas o codificador para fins de treinamento. Os transformadores também levaram ao desenvolvimento de sistemas pré-treinados, como transformadores generativos pré-treinados (GPTs) e BERT, que revolucionaram as tarefas de PNL. A atenção cruzada é uma variação em que o modelo usa sequências de entrada diferentes, aprimorando as relações entre duas sequências diferentes.
7. Saída final
O decodificador constrói a resposta final, garantindo precisão gramatical e preservação do contexto. Em nosso exemplo de tradução,
“Como você está hoje?” → “Como isso vai hoje?”
Conceitos-chave na arquitetura de transformadores
Mecanismo de autoatenção
A autoatenção permite que o modelo se concentre em relacionamentos importantes entre palavras. Por exemplo, em: “O gato estava sentado no tapete. Era macio.” O modelo entende que “Isso” refere-se a “o tapete”, em vez de “o gato”, tornando-o mais contextualmente consciente.
A atenção ao produto Scaled Dot é um mecanismo crítico de autoatenção empregado na arquitetura de transformadores. Ele funciona integrando três matrizes de peso — consulta, chave e valor — para calcular os pesos de atenção, que determinam a importância de diferentes elementos da sequência durante o processamento. A atenção escalonada do produto pontual é a forma de autoatenção mais usada na prática.
Atenção com várias cabeças
Em vez de olhar apenas um relacionamento de cada vez, atenção multifacetada permite que o modelo analise muitos aspectos de significado de uma só vez. Os transformadores usam uma configuração de atenção com várias cabeças. Nessa configuração, cada cabeça analisa diferentes relações entre os tokens. Os transformadores utilizam um mecanismo de atenção com várias cabeças, em que cada cabeça de atenção captura diferentes tipos de relações entre os tokens. Isso aprimora a capacidade do modelo de:
- Reconhecer sinônimos
- Capture nuances na linguagem
- Entenda estruturas de frases complexas
Codificação posicional
Como os transformadores não processam texto sequencialmente como os modelos mais antigos, eles confiam em codificação posicional para entender a ordem das palavras. Isso evita confusão entre frases semelhantes, como:
“Ela o ama.”
“Ele a ama.”
Sem codificação posicional, ambas as frases podem parecer igualmente válidas.
Preparação e entrada de dados
A preparação de dados é a base de qualquer projeto de aprendizado profundo, e os modelos de transformadores não são exceção. A jornada começa com os dados de entrada, que normalmente consistem em dados sequenciais, como texto ou fala. Esses dados brutos precisam ser pré-processados para torná-los adequados ao modelo. Nuvem os fornecedores geralmente fornecem serviços para simplificar os processos de ETL (Extrair, Transformar, Carregar), simplificando a preparação de dados para projetos de aprendizado profundo.
A primeira etapa do pré-processamento é a tokenização. Isso envolve dividir o texto de entrada em unidades menores chamadas tokens. Os tokens podem ser considerados palavras, subpalavras ou caracteres, dependendo do idioma e do modelo que você está usando. Por exemplo, a frase “Como você está hoje?” pode ser tokenizado em [“Como”, “estão”, “você”, “hoje”, “?”].
Uma vez tokenizados, esses tokens são convertidos em representações numéricas conhecidas como embeddings. As incorporações são vetores que capturam o significado semântico dos tokens, permitindo que o modelo os processe de forma eficaz. Cada token na sequência de entrada é representado como um vetor e, portanto, toda a sequência de entrada é transformada em uma sequência de vetores.
O comprimento da sequência de entrada pode variar, mas para um determinado modelo, normalmente é fixo. Isso garante a consistência e permite que o modelo manipule os dados com eficiência. A preparação adequada dos dados e a formatação de entrada são cruciais para o treinamento e o desempenho bem-sucedidos dos modelos de transformadores.
Treinamento e ajuste fino
O treinamento de modelos de transformadores é um processo que consome muitos recursos e envolve a otimização dos parâmetros do modelo usando um vasto corpus de dados de texto. Esses dados podem ser tão extensos quanto a Wikipedia inteira ou uma grande coleção de livros. O pré-treinamento de transformadores é feito usando aprendizado autosupervisionado em grandes conjuntos de dados, permitindo que os modelos aprendam padrões e relacionamentos sem exigir dados rotulados. O objetivo é minimizar a função de perda, que mede a diferença entre as previsões do modelo e os rótulos reais. Monitorar o desempenho do modelo ao longo do tempo é essencial após a implantação de um modelo de aprendizado profundo e serviços em nuvem fornecer ferramentas para esse fim.
O processo de treinamento exige uma potência computacional significativa, muitas vezes exigindo o uso de alto desempenho GPUs e grandes quantidades de memória. Esses recursos permitem que o modelo processe grandes conjuntos de dados e realize cálculos complexos com eficiência.
Depois que um modelo de transformador é pré-treinado, ele pode ser ajustado para tarefas ou conjuntos de dados específicos. O ajuste fino envolve o ajuste dos parâmetros do modelo para melhor se adequar aos novos dados, mantendo o conhecimento adquirido durante o treinamento inicial. Esse processo é menos exigente computacionalmente do que o treinamento do zero e pode ser feito com um conjunto de dados menor.
O ajuste fino é particularmente útil para adaptar modelos pré-treinados a novos idiomas, domínios ou tarefas. Por exemplo, um modelo pré-treinado em texto em inglês pode ser ajustado para funcionar bem em textos em francês ou em tarefas especializadas, como análise de sentimentos ou classificação de textos médicos.
Computação com Hivenet: a infraestrutura ideal para o treinamento de modelos de IA
Correndo LLMs como GPT requer recursos computacionais massivos. Aqui é onde Computação com Hivenet chega, fornecendo uma infraestrutura de nuvem robusta que suporta tecnologias avançadas, como IA e aprendizado de máquina. A escalabilidade e a acessibilidade de seus serviços, juntamente com opções versáteis de GPU e uma extensa centro de dados rede, permite a rápida implantação de modelos de IA. O Google Cloud Platform fornece máquinas virtuais com GPUs NVIDIA, incluindo Tesla K80, P4, T4, P100 e V100. O Hyperstack fornece acesso a GPUs NVIDIA de alto desempenho, incluindo H100 e A100 para cargas de trabalho exigentes.
Além disso, Computação com Hivenet oferece hardware especializado, como GPUs e TPUs, necessário para executar cargas de trabalho de aprendizado profundo com eficiência. Isso permite que os usuários implantem uma infraestrutura de aprendizado profundo e gerenciem todo o pipeline, desde a ingestão de dados até a implantação da produção. O AWS Deep Learning AMI é uma imagem de máquina EC2 personalizada projetada para aplicativos de aprendizado profundo. O Lambda Labs oferece acesso a poderosas GPUs NVIDIA para desenvolvimento de IA, a partir de 2,49 USD por hora para o H100 PCIe.
Exemplo do mundo real: educação baseada em IA com computação com Hivenet
Uma das aplicações mais promissoras do computação distribuída para IA está na educação. MyTutor.io, uma empresa que utiliza a IA para tutoria personalizada, escalou com sucesso suas operações usando Computação com Hivenet. Em um entrevista com Anton Gorelov, cofundador e CTO da MyTutor.io, ele explica como A infraestrutura de computação em nuvem escalável da Hivenet possibilitou o treinamento e a implantação de modelos de IA que oferecem experiências de aprendizado adaptáveis para estudantes em todo o mundo.
Por que usar a computação com a Hivenet para treinamento de transformadores?
- Computação em nuvem descentralizada: Ao contrário dos serviços de nuvem tradicionais, A Hivenet aproveita a computação distribuída, reduzindo a dependência de servidores centralizados para uma melhor alocação de recursos.
- Escalabilidade: Precisa de mais computação? A Hivenet aloca recursos dinamicamente com base na demanda.
- Rapidez: O arquitetura distribuída minimiza os gargalos de treinamento, otimizando Treinamento e inferência de modelos de IA.
Se você está desenvolvendo Modelos de IA, Computação com Hivenet fornece um mais flexível, eficiente e acessível alternativa ao tradicional computação em nuvem para IA.
Aprendizado profundo na nuvem
O aprendizado profundo na nuvem revolucionou a forma como treinamos e implantamos modelos de aprendizado profundo, oferecendo uma alternativa escalável e flexível à infraestrutura local tradicional. Ao alavancar computação em nuvem com recursos, você pode acessar hardware e ferramentas poderosos sem a necessidade de um investimento inicial significativo. A maioria das plataformas de nuvem fornece serviços de IA pré-treinados que podem alcançar alta precisão para casos de uso geral e estão prontos para uso imediato. Serviços de computação em nuvem melhore a acessibilidade do aprendizado profundo simplificando o gerenciamento de grandes conjuntos de dados e facilitando o treinamento em hardware distribuído. O Paperspace oferece suporte a várias GPUs NVIDIA para o desenvolvimento de modelos de IA, com preços a partir de 2,24 dólares por hora para a GPU H100.
Os principais provedores de nuvem, como AWS, Google Cloud e Microsoft Azure, oferecem uma variedade de serviços de aprendizado profundo. Isso inclui modelos, estruturas e ferramentas pré-construídos que simplificam o processo de treinamento e implantação de modelos. Por exemplo, o Google Cloud oferece uma variedade de serviços de aprendizado de máquina chamados Cloud AI, que incluem serviços especializados para aplicativos de aprendizado profundo. A Amazon Web Services oferece um serviço de aprendizado de máquina totalmente gerenciado chamado SageMaker para aprendizado profundo, permitindo que os usuários criem, treinem e implantem modelos com eficiência. Escolher o provedor de nuvem certo para o aprendizado profundo exige avaliar os recursos, os preços e as necessidades específicas de sua carga de trabalho. Os serviços de aprendizado profundo baseados em nuvem permitem fácil integração com notebooks, facilitando a transição perfeita de trabalhos de treinamento para instâncias de computação baseadas em nuvem.
Uma das principais vantagens do aprendizado profundo na nuvem é sua relação custo-benefício. Você paga apenas pelos recursos que usa, o que o torna uma opção econômica tanto para projetos de grande escala quanto para experimentos menores. Além disso, os serviços em nuvem oferecem a flexibilidade de ampliar ou ampliar seus esforços de treinamento e implantação com base nas necessidades do seu projeto. A plataforma de nuvem Nebius fornece instâncias NVIDIA aceleradas por GPU para cargas de trabalho de IA e aprendizado profundo.
Ao utilizar o aprendizado profundo na nuvem, você pode se concentrar no desenvolvimento e no ajuste fino de seus modelos enquanto o provedor de nuvem gerencia a infraestrutura subjacente. Essa abordagem não só economiza tempo e dinheiro, mas também permite que você aproveite os últimos avanços na tecnologia de aprendizado profundo.
Conclusão
A arquitetura do transformador reformulou a IA, tornando geração de texto semelhante à humana possível. Se você estiver treinando modelos de IA, Computação com Hivenet oferece um infraestrutura poderosa, escalável e econômica.
Pronto para escalar seus projetos de IA? Comece a usar o Compute with Hivenet hoje mesmo!
Perguntas frequentes (muito) abrangentes
Arquitetura e computação de transformadores com Hivenet
Como a IA baseada em transformadores difere dos modelos tradicionais de aprendizado profundo?
Uso de transformadores autoatenção e processamento paralelo, enquanto modelos tradicionais, como RNNs, processam texto sequencialmente, tornando-os mais lentos e menos sensíveis ao contexto. Além disso, os transformadores não têm unidades recorrentes, o que reduz o tempo de treinamento em comparação com arquiteturas neurais recorrentes anteriores. A autoatenção permite que o modelo processe todos os tokens em uma sequência simultaneamente, permitindo assim a paralelização dos cálculos.
Quais são os requisitos de hardware para treinar um modelo de transformador?
O treinamento de transformadores requer GPUs ou TPUs de alto desempenho, memória significativa e recursos de nuvem distribuídos, como Computação com Hivenet.
Como a computação com a Hivenet otimiza o treinamento de IA?
Hivenet's computação descentralizada aloca recursos dinamicamente, reduzindo os custos da nuvem e aumentando a eficiência. O Vultr oferece uma variedade de opções de GPU acessíveis, incluindo NVIDIA A100 e H100.
Projetos de IA de pequena escala podem se beneficiar da computação com a Hivenet?
Sim! Computar com Hivenet é escalável, tornando-o adequado para ambos treinamento corporativo de IA e experimentos menores de IA.Como posso começar a usar o Compute com o Hivenet?
Inscreva-se em https://compute.hivenet.com/ para acessar recursos de computação de IA.
Arquitetura de transformadores e modelos de linguagem grande (LLMs)
O que é a arquitetura Transformer no GPT?
O Arquitetura do transformador no GPT é um modelo de aprendizado profundo projetado para processamento de linguagem natural (PNL). Ele se baseia em autoatenção e camadas de alimentação para processar texto em paralelo, permitindo que ele entenda contexto, dependências e relações entre palavras em longas distâncias.
Qual é a diferença entre a arquitetura CNN e Transformer?
- CNNs (redes neurais convolucionais) são usados principalmente para processamento de imagem e confiam em camadas convolucionais para detectar padrões em campos receptivos locais.
- Transformadores são projetados para processamento de texto e use mecanismos de autoatenção para capturar dependências de longo alcance em sequências.
O que é arquitetura Transformer em LLMs?
Em Modelos de linguagem grande (LLMs), A arquitetura do transformador permite eficiência processamento de texto, geração e compreensão contextual. Ele usa autoatenção, atenção com várias cabeças e camadas de avanço para processar grandes quantidades de texto.
Qual é a diferença entre a arquitetura BERT e Transformer?
O BERT é uma implementação específica do Arquitetura do transformador, mas difere em aspectos fundamentais:
- BERT é bidirecional, o que significa que considera o contexto de ambos esquerda e direita de uma palavra.
- Transformadores padrão (como GPT) são tipicamente autorregressivo, processando texto um direcionalmente da esquerda para a direita.
Modelos de linguagem grande (LLMs) e PNL
O que é um modelo de linguagem grande?
UM Modelo de linguagem grande (LLM) é um sistema de IA treinado em grandes conjuntos de dados para entender e gerar texto semelhante ao humano. Os exemplos incluem GPT-4, BERT e PalM.
O ChatGPT é um grande modelo de linguagem?
Sim, o ChatGPT é baseado em GPT, que é um modelo de linguagem grande (LLM) treinado para gerar e processar texto.
Qual é a diferença entre BERT e LLM?
- BERT é um LLM, mas se concentra em aprendizagem contextual bidirecional para tarefas de PNL.
- LLMs (como GPT-4) são geralmente autorregressivo, treinado para geração e preenchimento de texto.
Qual rede neural é usada para PNL?
O Transformador a arquitetura é a rede neural mais comum para a PNL atualmente.
Por que usar RNN para PNL?
RNNs (redes neurais recorrentes) foram usadas antes dos transformadores para processar texto sequencial, mas lutou com dependências de longo alcance.
Quais são os 4 tipos de PNL?
- Classificação de texto (por exemplo, detecção de spam)
- Reconhecimento de entidade nomeada (NER) (por exemplo, nomes de identificação)
- Tradução automática (por exemplo, Google Translate)
- Análise de sentimentos (por exemplo, mineração de opinião)
Qual rede neural é melhor para processamento de texto?
Transformadores superam RNNs e CNNs no processamento de texto devido à sua paralelização e mecanismos de autoatenção.
Treinamento de modelos de IA e computação em nuvem
O que é treinamento de modelos em IA?
O treinamento de modelos é o processo de inserir dados em um sistema de IA para ajudá-lo a aprender padrões, relacionamentos e previsões.
Onde obter modelos de IA treinados?
Modelos de IA pré-treinados estão disponíveis em plataformas como Hugging Face, TensorFlow Hub e API OpenAI.
É difícil treinar um modelo de IA?
O treinamento de modelos de IA exige dados, poder de computação e técnicas de otimização mas pode ser simplificado com plataformas de treinamento de IA baseadas em nuvem.
Quais são os 4 modelos de IA?
- Máquinas reativas (por exemplo, IA de xadrez Deep Blue)
- IA de memória limitada (por exemplo, self-dirigindo carros)
- Teoria da mente AI (hipotético)
- IA autoconsciente (hipotético)
O que é processamento de linguagem natural?
A PNL é o campo da IA que permite aos computadores compreender, interpretar e gerar linguagem humana.
O que é PNL e exemplos?
Exemplos de PNL incluem chatbots, tradução automática e assistentes de voz.
A PNL é aprendizado de máquina ou IA?
A PNL é uma subconjunto de IA que usa técnicas de aprendizado de máquina.
Qual é a diferença entre PNL e NLM?
- PNL (processamento de linguagem natural) se concentra na compreensão do texto.
- NLM (modelo de linguagem neural) é um modelo de aprendizado profundo que prevê a próxima palavra em uma sequência.
Infraestrutura de inteligência artificial e aprendizado de máquina na nuvem
Qual provedor de nuvem é melhor para IA?
Hivenet é a melhor escolha para cargas de trabalho de IA.
Qual certificação de IA na nuvem é a melhor?
O Aprendizado de máquina certificado pela AWS — Especialidade e Engenheiro de ML profissional do Google as certificações são altamente valorizadas.
Qual é a melhor plataforma para aprender IA?
Coursera, Udacity e fast.ai oferecem ótimos programas de aprendizado de IA.
Como treinar modelos de IA na nuvem?
Uso plataformas de nuvem como Compute with Hivenet, AWS SageMaker ou Google AI Platform.
Como a IA pode ser usada na computação em nuvem?
A IA é usada em escalabilidade automática, análise preditiva e tecnologia de inteligência artificial segurança na nuvem.d) segurança na nuvem.

