

Iniciar sesión en Hivenet
Acceda a sus archivos y administre su cuenta de almacenamiento.
Tienda
Acceda a sus archivos y administre su cuenta de almacenamiento.
Calcular
Lanza instancias y administra tus recursos informáticos.
En la actualidad, Store y Compute siguen utilizando cuentas distintas. Estamos trabajando en un inicio de sesión unificado.
¿Solo necesitas enviar un archivo?
Usa Enviar directamente¿Eres nuevo en Hivenet? Comenzar
Comience con Hivenet
Elige lo que quieres usar primero.
Tienda
Realiza copias de seguridad de fotos y archivos en todos tus dispositivos.
Calcular
Lance la computación de GPU de autoservicio para trabajos exigentes.
En la actualidad, Store y Compute siguen utilizando cuentas distintas. Estamos trabajando en una experiencia de cuenta unificada.
¿Necesitas Hivenet para tu empresa?
Hable con el departamento de ventas¿Necesitas enviar un archivo?
Abrir Enviar¿Ya tienes una cuenta? Iniciar sesión
Contacta con Hivenet
Elige la ruta que se ajuste a tu pregunta.
Contacto general
Preguntas, soporte, asociaciones, prensa o cualquier otra cosa que no esté relacionada con una conversación de ventas.
Hable con el departamento de ventas
Pregunte acerca de la computación, el almacenamiento, la IA privada o una implementación empresarial más grande.
¿Necesitas ayuda con la configuración, la facturación o la solución de problemas? Comience con Soporte para obtener la respuesta más rápida.
Simplificación de la arquitectura de transformadores: una guía para principiantes sobre cómo entender la magia de la IA

La inteligencia artificial (IA) ha transformado la forma en que interactuamos con la tecnología y ha impulsado todo, desde los chatbots hasta la traducción automática avanzada. En el centro de esta revolución se encuentra arquitectura de transformadores, la columna vertebral de modelos lingüísticos extensos (LLM) como GPT, BERT y T5. Pero si alguna vez has intentado entender cómo estos modelos de aprendizaje profundo trabajo, es probable que te hayas encontrado con un laberinto de jerga técnica.
La arquitectura transformadora original, inicialmente diseñada para tareas de traducción, sentó las bases para varias adaptaciones en los modelos lingüísticos modernos. Se introdujo en junio de 2017 y supuso un hito importante en la evolución de la IA.
¿La buena noticia? Modelos de transformadores en IA no son tan complicados como parecen. Al dividirlos en partes digeribles, puedes comprender sus principios básicos y entender cómo procesan y generan textos similares a los humanos. Esta guía simplifica arquitectura de transformadores, explicando sus componentes de forma accesible tanto para los principiantes como para los entusiastas de la IA.
¿Qué es la arquitectura Transformer?
Arquitectura de transformadores es un red neuronal para PNL (procesamiento del lenguaje natural), diseñado para procesar secuencial dato (como texto) en paralelo, en lugar de hacerlo palabra por palabra, lo que lo hace más eficiente que los modelos más antiguos, como redes neuronales recurrentes (RNN) y memoria a corto plazo (LSTM).
A diferencia de los modelos tradicionales que analizan las palabras de una en una, los transformadores aprovechan los mecanismos de autoatención para entender las relaciones entre las palabras a lo largo de una oración completa. Esto les permite generar respuestas más precisas y adaptadas al contexto, lo que las hace esenciales para tareas como el procesamiento del lenguaje natural a gran escala y las aplicaciones de visión artificial.
- Traducción automática
- Resumen de textos
- Análisis de sentimientos
- IA conversacional
- Generación de código
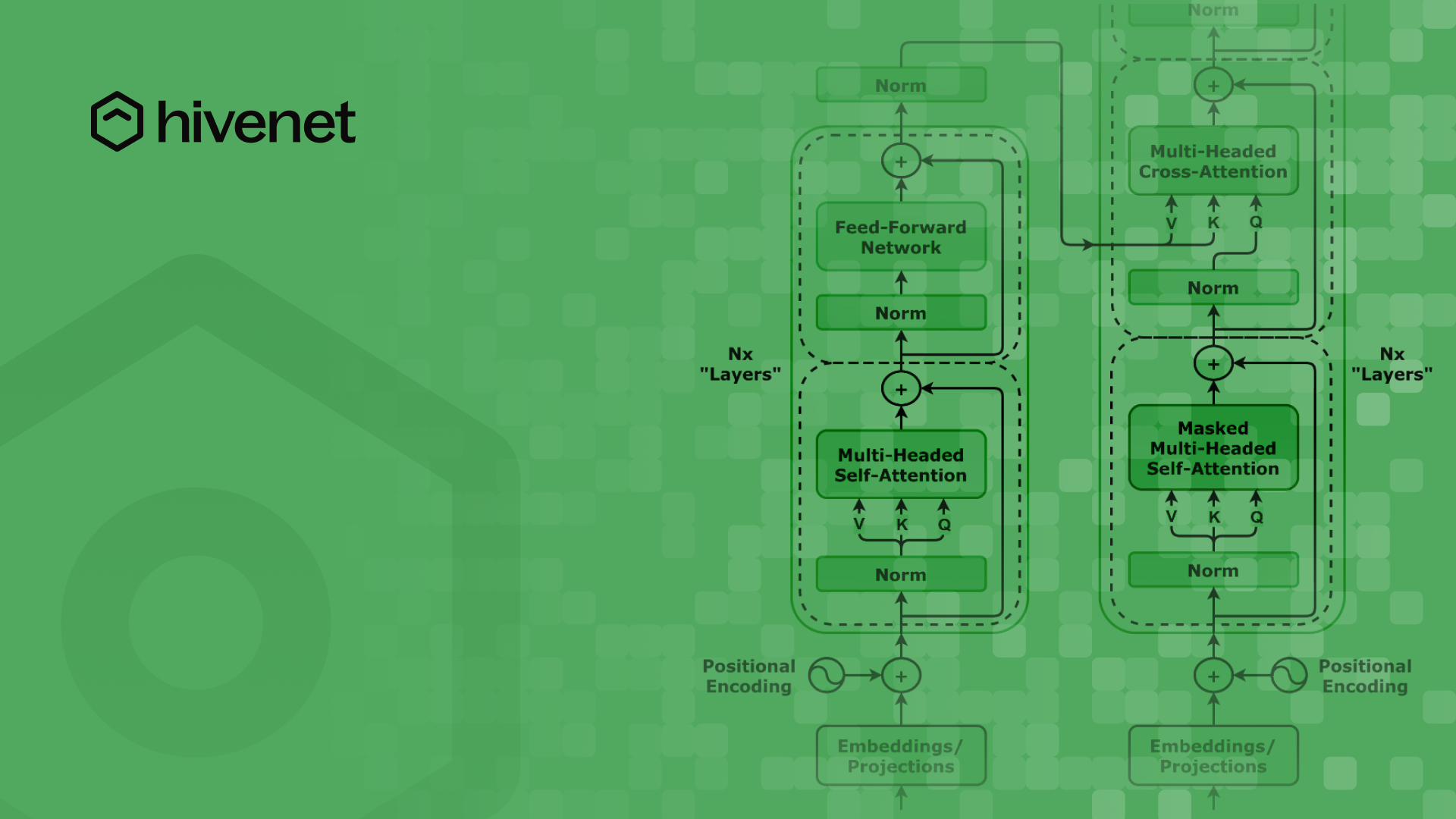
El modelo de transformador original introdujo la arquitectura codificador-decodificador, que incluye mecanismos de autoatención tanto en la capa del codificador como en la del decodificador. Los modelos de codificador-decodificador son cruciales para tareas como la generación de texto y el aprendizaje de la representación. Se diferencian de las configuraciones de solo codificador y solo decodificador porque combinan procesos de codificación y decodificación, lo que mejora su aplicación en diversas tareas de PNL.
Vamos a explorar cómo funcionan los transformadores en la IA, paso a paso.
Desglose paso a paso de la arquitectura del transformador
1. Ingresa el texto
El proceso comienza con una oración de entrada determinada, como: «¿Cómo estás hoy?»
2. Tokenización
Antes de introducir el texto en el modelo, es tokenizado—lo que significa que se divide en partes más pequeñas (fichas). Estas pueden ser:
- Palabras (p. ej., ["Cómo», «estás», «tú», «hoy», «?"])
- Subpalabras (p. ej., ["Cómo», «estás», «tú», «para», «día», «?"])
- Personajes (para idiomas específicos como el chino o el japonés)
3. Incrustaciones de palabras y codificación posicional
Cada token se convierte en un incrustación, una representación numérica que captura su significado. Sin embargo, dado modelos de transformadores procesan todas las palabras simultáneamente, necesitan una forma de reconocer el orden de las palabras. Esto se logra mediante codificación posicional, que asigna incrustaciones sinusoidales o aprendidas para indicar las posiciones de las palabras, asegurándose de que el modelo comprenda el orden de las secuencias.
4. Pasando por el codificador
El codificador consta de varias capas de unidades de procesamiento, cada una con dos componentes clave:
- Mecanismo de autoatención: Ayuda al modelo a centrarse en las palabras más relevantes al analizar el texto. Este mecanismo emplea tres matrices de ponderación para derivar secuencias de consultas, claves y valores a partir de los datos de entrada, destacando las relaciones dimensionales y las operaciones matriciales esenciales para ejecutar los cálculos de atención. Cada capa de codificación de un transformador contiene un mecanismo de autoatención y una red neuronal de retroalimentación.
- Red neuronal de retroalimentación: Mejora la capacidad del modelo para captar relaciones más profundas entre las palabras.
Por ejemplo, en «¿Cómo estás hoy?», la autoatención ayuda al modelo a reconocer que «tú» está estrechamente vinculado a «son», garantizando una estructura de oración adecuada en el producto final.
5. Generación de vectores de incrustación
Las salidas del codificador incrustar vectores, que son representaciones numéricas que encapsulan el significado del texto. Estos vectores se introducen luego en el decodificador.
6. El decodificador genera la salida
El decodificador se encarga de generar el texto, trabajando de forma secuencial:
- Es comienza con una palabra inicial (p. ej., «Comentario» para una traducción al francés).
- Es utiliza salidas de codificador y palabras generadas previamente para predecir la siguiente palabra.
- Es itera este proceso hasta que se forme una oración completa.
Los modelos de solo decodificador, como los primeros modelos GPT, utilizan solo el componente de decodificador de la arquitectura del transformador para predecir el siguiente token de una secuencia. Esto contrasta con los modelos de codificador-decodificador como BERT, que solo emplean el codificador con fines de formación. Los transformadores también han llevado al desarrollo de sistemas preentrenados, como los transformadores generativos preentrenados (GPT) y el BERT, que han revolucionado las tareas de la PNL. La atención cruzada es una variación en la que el modelo utiliza diferentes secuencias de entrada, lo que mejora las relaciones entre dos secuencias diferentes.
7. Salida final
El decodificador construye la respuesta final, garantizando la precisión gramatical y la preservación del contexto. En nuestro ejemplo de traducción,
«¿Cómo estás hoy?» → «¿Comment ça va aujourd'hui?»
Conceptos clave en la arquitectura de transformadores
Mecanismo de autoatención
La autoatención permite que el modelo se centre en relaciones importantes entre palabras. Por ejemplo, en: «El gato se sentó en la colchoneta. Era suave». La modelo lo entiende «Eso» se refiere a «la alfombra», en lugar de «el gato», haciéndolo más consciente del contexto.
La atención al producto con puntos escalados es un mecanismo de autoatención fundamental que se emplea en la arquitectura de transformadores. Funciona integrando tres matrices de ponderación (consulta, clave y valor) para calcular las ponderaciones de atención, que determinan la importancia de los diferentes elementos de la secuencia durante el procesamiento. La atención escalonada por puntos es la forma de autoatención más utilizada en la práctica.
Atención multicabezal
En lugar de mirar solo uno relación a la vez, atención multicabezal permite que el modelo analice muchos aspectos significativos de una vez. Los transformadores utilizan una configuración de atención con varios cabezales. En esta configuración, cada cabeza analiza las diferentes relaciones entre las fichas. Los transformadores utilizan un mecanismo de atención con varios cabezales, en el que cada cabezal de atención captura diferentes tipos de relaciones entre los símbolos. Esto mejora la capacidad del modelo para:
- Reconocer sinónimos
- Captura los matices del lenguaje
- Comprenda las estructuras complejas de las oraciones
Codificación posicional
Dado que los transformadores no procesan el texto de forma secuencial como los modelos anteriores, se basan en codificación posicional para entender el orden de las palabras. Esto evita la confusión entre oraciones similares, como:
«Ella lo ama».
«Él la ama».
Sin codificación posicional, ambas frases pueden parecer igualmente válidas.
Preparación e ingreso de datos
La preparación de datos es la piedra angular de cualquier proyecto de aprendizaje profundo, y los modelos de transformadores no son la excepción. El recorrido comienza con los datos de entrada, que normalmente consisten en datos secuenciales, como texto o voz. Estos datos sin procesar deben procesarse previamente para que sean adecuados para el modelo. Nube los proveedores suelen ofrecer servicios para simplificar los procesos de ETL (extracción, transformación y carga), lo que agiliza la preparación de datos para los proyectos de aprendizaje profundo.
El primer paso del preprocesamiento es la tokenización. Esto implica dividir el texto introducido en unidades más pequeñas llamadas fichas. Los símbolos se pueden considerar como palabras, subpalabras o caracteres, según el idioma y el modelo que utilices. Por ejemplo, la frase «¿Cómo estás hoy?» podría tokenizarse en [«Cómo», «estás», «tú», «hoy», «?»].
Una vez tokenizados, estos tokens se convierten en representaciones numéricas conocidas como incrustaciones. Las incrustaciones son vectores que capturan el significado semántico de los tokens, lo que permite que el modelo los procese de manera efectiva. Cada token de la secuencia de entrada se representa como un vector y, por lo tanto, toda la secuencia de entrada se transforma en una secuencia de vectores.
La longitud de la secuencia de entrada puede variar, pero para un modelo determinado, normalmente es fija. Esto garantiza la coherencia y permite que el modelo gestione los datos de manera eficiente. La preparación adecuada de los datos y el formato de entrada son cruciales para el entrenamiento y el rendimiento exitosos de los modelos de transformadores.
Entrenamiento y puesta a punto
El entrenamiento de modelos transformadores es un proceso que consume muchos recursos y que implica la optimización de los parámetros del modelo utilizando un vasto corpus de datos de texto. Estos datos pueden ser tan extensos como toda la Wikipedia o una gran colección de libros. El entrenamiento previo de los transformadores se realiza mediante el aprendizaje autosupervisado en grandes conjuntos de datos, lo que permite a los modelos aprender patrones y relaciones sin necesidad de etiquetar datos. El objetivo es minimizar la función de pérdida, que mide la diferencia entre las predicciones del modelo y las etiquetas reales. Supervisar el rendimiento del modelo a lo largo del tiempo es esencial después de implementar un modelo de aprendizaje profundo, y servicios en la nube proporcionar herramientas para este propósito.
El proceso de entrenamiento requiere una potencia computacional significativa y, a menudo, requiere el uso de sistemas de alto rendimiento GPUs y grandes cantidades de memoria. Estos recursos permiten al modelo procesar grandes conjuntos de datos y realizar cálculos complejos de manera eficiente.
Una vez que se entrena previamente un modelo de transformador, se puede ajustar para tareas o conjuntos de datos específicos. El ajuste fino implica ajustar los parámetros del modelo para que se ajusten mejor a los nuevos datos y, al mismo tiempo, conservar los conocimientos adquiridos durante la capacitación inicial. Este proceso es menos exigente desde el punto de vista computacional que el entrenamiento desde cero y se puede realizar con un conjunto de datos más pequeño.
El ajuste fino es particularmente útil para adaptar modelos previamente entrenados a nuevos lenguajes, dominios o tareas. Por ejemplo, un modelo previamente entrenado en texto en inglés se puede ajustar para que funcione bien en texto en francés o en tareas especializadas, como el análisis de opiniones o la clasificación de textos médicos.
Compute con Hivenet: la infraestructura ideal para el entrenamiento de modelos de IA
Corriendo LLMs como GPT requiere recursos computacionales masivos. Aquí es donde Compute con Hivenet entra en juego, proporcionando una sólida infraestructura de nube que admite tecnologías avanzadas como la inteligencia artificial y el aprendizaje automático. La escalabilidad y la asequibilidad de sus servicios, junto con las versátiles opciones de GPU y una amplia centro de datos red, permiten un despliegue rápido de modelos de IA. Google Cloud Platform proporciona máquinas virtuales con GPU NVIDIA, incluidas las Tesla K80, P4, T4, P100 y V100. Hyperstack proporciona acceso a las GPU NVIDIA de alto rendimiento, incluidas la H100 y la A100, para cargas de trabajo exigentes.
Además, Compute con Hivenet ofrece el hardware especializado, como GPU y TPU, necesario para ejecutar de manera eficiente las cargas de trabajo de aprendizaje profundo. Esto permite a los usuarios implementar una infraestructura de aprendizaje profundo y gestionar todo el proceso, desde la ingesta de datos hasta la implementación en producción. La AMI de aprendizaje profundo de AWS es una imagen de máquina de EC2 personalizada diseñada para aplicaciones de aprendizaje profundo. Lambda Labs ofrece acceso a potentes GPU de NVIDIA para el desarrollo de IA, a partir de 2,49 dólares la hora para la PCIe H100.
Ejemplo del mundo real: educación basada en inteligencia artificial con computación con Hivenet
Una de las aplicaciones más prometedoras de computación distribuida para IA se dedica a la educación. MyTutor.io, una empresa que aprovecha la IA para ofrecer tutorías personalizadas, ha escalado con éxito sus operaciones utilizando Compute con Hivenet. En un entrevista con Anton Gorelov, cofundador y director de tecnología de MyTutor.io, explica cómo Infraestructura escalable de computación en la nube de Hivenet ha permitido la formación y el despliegue de modelos de IA que ofrecen experiencias de aprendizaje adaptables a estudiantes de todo el mundo.
¿Por qué usar Compute con Hivenet para el entrenamiento de Transformer?
- Computación en la nube descentralizada: A diferencia de los servicios en la nube tradicionales, Hivenet aprovecha la computación distribuida, lo que reduce la dependencia de servidores centralizados para una mejor asignación de recursos.
- Escalabilidad: ¿Necesitas más procesamiento? Hivenet asigna recursos de forma dinámica en función de la demanda.
- Velocidad: El arquitectura distribuida minimiza los cuellos de botella en la formación, optimizando Entrenamiento e inferencia de modelos de IA.
Si te estás desarrollando Modelos de IA, Compute con Hivenet proporciona un más flexible, eficiente y asequible alternativa a lo tradicional computación en nube para IA.
Aprendizaje profundo en la nube
El aprendizaje profundo en la nube ha revolucionado la forma en que entrenamos e implementamos los modelos de aprendizaje profundo, al ofrecer una alternativa escalable y flexible a la infraestructura local tradicional. Aprovechando computación en nube recursos, puede acceder a herramientas y hardware potentes sin necesidad de realizar una inversión inicial significativa. La mayoría de las plataformas en la nube ofrecen servicios de IA previamente entrenados que pueden lograr una alta precisión para casos de uso general y están listos para usarse de inmediato. Servicios de computación en nube mejorar la accesibilidad del aprendizaje profundo simplificando la administración de grandes conjuntos de datos y facilitando la capacitación en hardware distribuido. Paperspace es compatible con varias GPU NVIDIA para el desarrollo de modelos de IA, con precios que comienzan en 2,24 dólares la hora para la GPU H100.
Los principales proveedores de nube, como AWS, Google Cloud y Microsoft Azure, ofrecen una gama de servicios de aprendizaje profundo. Estos incluyen modelos, marcos y herramientas prediseñados que simplifican el proceso de entrenamiento e implementación de modelos. Por ejemplo, Google Cloud ofrece una variedad de servicios de aprendizaje automático denominados Cloud AI, que incluye servicios especializados para aplicaciones de aprendizaje profundo. Amazon Web Services ofrece un servicio de aprendizaje automático totalmente administrado llamado SageMaker para el aprendizaje profundo, que permite a los usuarios crear, entrenar e implementar modelos de manera eficiente. La elección del proveedor de nube adecuado para el aprendizaje profundo requiere evaluar las funciones, los precios y las necesidades específicas de su carga de trabajo. Los servicios de aprendizaje profundo basados en la nube permiten una integración sencilla con los ordenadores portátiles, lo que facilita la transición sin problemas de los trabajos de formación a las instancias informáticas basadas en la nube.
Una de las principales ventajas del aprendizaje profundo en la nube es su rentabilidad. Solo paga por los recursos que utiliza, por lo que es una opción económica tanto para proyectos a gran escala como para experimentos más pequeños. Además, los servicios en la nube brindan la flexibilidad de ampliar o escalar tus esfuerzos de capacitación e implementación en función de las necesidades de tu proyecto. La plataforma en la nube de Nebius proporciona instancias aceleradas por GPU de NVIDIA para cargas de trabajo de inteligencia artificial y aprendizaje profundo.
Al utilizar el aprendizaje profundo en la nube, puede centrarse en desarrollar y ajustar sus modelos mientras el proveedor de la nube se encarga de la infraestructura subyacente. Este enfoque no solo ahorra tiempo y dinero, sino que también le permite aprovechar los últimos avances en la tecnología de aprendizaje profundo.
Conclusión
La arquitectura Transformer ha remodelado la IA, haciendo generación de texto similar a la humana posible. Si estás entrenando modelos de IA, Compute con Hivenet ofrece un infraestructura potente, escalable y rentable.
¿Estás listo para escalar tus proyectos de IA? ¡Empieza a usar Compute with Hivenet hoy mismo!
Preguntas frecuentes (muy) completas
Arquitectura de transformadores y computación con Hivenet
¿En qué se diferencia la IA basada en transformadores de los modelos tradicionales de aprendizaje profundo?
Uso de transformadores autoatención y procesamiento paralelo, mientras que los modelos tradicionales, como las RNN, procesan el texto de forma secuencial, lo que los hace más lentos y menos sensibles al contexto. Además, los transformadores no tienen unidades recurrentes, lo que reduce el tiempo de entrenamiento en comparación con las arquitecturas neuronales recurrentes anteriores. La autoatención permite que el modelo procese todos los tokens de una secuencia simultáneamente, lo que permite la paralelización de los cálculos.
¿Cuáles son los requisitos de hardware para entrenar un modelo de transformador?
La formación de transformadores requiere GPU o TPU de alto rendimiento, una cantidad significativa de memoria y recursos de nube distribuidos, como Compute con Hivenet.
¿Cómo optimiza Compute con Hivenet el entrenamiento de la IA?
Hivenet computación descentralizada asigna los recursos de forma dinámica, lo que reduce los costos de la nube y aumenta la eficiencia. Vultr ofrece una gama de opciones de GPU asequibles, incluidas las NVIDIA A100 y H100.
¿Pueden los proyectos de IA a pequeña escala beneficiarse de Compute con Hivenet?
¡Sí! Computar con Hivenet es escalable, lo que lo hace adecuado para ambos formación en IA empresarial y experimentos de IA más pequeños.¿Cómo puedo empezar a usar Compute con Hivenet?
Inscríbase en https://compute.hivenet.com/ para acceder a los recursos de cómputos de la IA.
Arquitectura de transformadores y modelos de lenguaje de gran tamaño (LLM)
¿Qué es la arquitectura Transformer en GPT?
El Arquitectura de transformadores en GPT es un modelo de aprendizaje profundo diseñado para procesamiento del lenguaje natural (PNL). Se basa en autoatención y capas de retroalimentación procesar el texto en paralelo, lo que le permite entender contexto, dependencias y relaciones entre palabras a largas distancias.
¿Cuál es la diferencia entre la arquitectura CNN y Transformer?
- CNN (redes neuronales convolucionales) se utilizan principalmente para procesamiento de imágenes y se basan en capas convolucionales para detectar patrones en los campos receptivos locales.
- Transformadores están diseñados para procesamiento de textos y usar mecanismos de autoatención para capturar dependencias de largo alcance en secuencias.
¿Qué es la arquitectura Transformer en los LLM?
En Modelos de lenguaje extensos (LLM), La arquitectura Transformer permite una eficiencia procesamiento, generación y comprensión contextual de textos. Utiliza capas de autoatención, atención con múltiples cabezas y retroalimentación para procesar grandes cantidades de texto.
¿Cuál es la diferencia entre la arquitectura BERT y Transformer?
BERT es una implementación específica del Arquitectura de transformadores, pero difiere en aspectos clave:
- BERTA es bidireccional, lo que significa que considera el contexto de ambos izquierda y derecha de una palabra.
- Transformadores estándar (como GPT) son típicamente autorregresivo, procesamiento de texto uno direccionalmente de izquierda a derecha.
Modelos de lenguaje extensos (LLM) y PNL
¿Qué es un modelo lingüístico grande?
UN Modelo de lenguaje grande (LLM) es un sistema de inteligencia artificial entrenado en conjuntos de datos masivos para comprender y generar texto similar al humano. Entre los ejemplos se incluyen GPT-4, BERT y PalM.
¿ChatGPT es un modelo de lenguaje grande?
Sí, ChatGPT se basa en GPT, que es un modelo de lenguaje grande (LLM) capacitado para generar y procesar texto.
¿Cuál es la diferencia entre BERT y LLM?
- BERTA es un LLM pero se centra en aprendizaje contextual bidireccional para tareas de PNL.
- LLM (como GPT-4) son generalmente autorregresivo, capacitado para la generación y finalización de textos.
¿Qué red neuronal se usa para la PNL?
El Transformador La arquitectura es la red neuronal más común para la PNL en la actualidad.
¿Por qué usar RNN para PNL?
Las RNN (redes neuronales recurrentes) se usaron antes de Transformers para procesar texto secuencial, pero tuvo problemas con las dependencias de largo alcance.
¿Cuáles son los 4 tipos de PNL?
- Clasificación de textos (p. ej., detección de spam)
- Reconocimiento de entidades nombradas (NER) (p. ej., nombres identificativos)
- Traducción automática (por ejemplo, Google Translate)
- Análisis de sentimientos (por ejemplo, minería de opiniones)
¿Qué red neuronal es mejor para el procesamiento de texto?
Transformadores superan a los RNN y CNN en el procesamiento de texto debido a sus paralelización y mecanismos de autoatención.
Entrenamiento de modelos de IA y computación en la nube
¿Qué es el entrenamiento de modelos en IA?
El entrenamiento de modelos es el proceso de introducir datos en un sistema de IA para ayudarlo a aprender patrones, relaciones y predicciones.
¿Dónde obtener modelos de IA entrenados?
Los modelos de IA previamente entrenados están disponibles en plataformas como Hugging Face, TensorFlow Hub y OpenAI API.
¿Es difícil entrenar un modelo de IA?
El entrenamiento de modelos de IA requiere datos, potencia informática y técnicas de optimización pero se puede simplificar con plataformas de entrenamiento de IA basadas en la nube.
¿Cuáles son los 4 modelos de IA?
- Máquinas reactivas (p. ej., Deep Blue chess AI)
- IA de memoria limitada (por ejemplo, por cuenta propiaconduciendo coches)
- Teoría de la mente (IA) (hipotético)
- IA autoconsciente (hipotético)
¿Qué es el procesamiento del lenguaje natural?
La PNL es el campo de la IA que permite a las computadoras entender, interpretar y generar el lenguaje humano.
¿Qué es la PNL y sus ejemplos?
Los ejemplos de PNL incluyen chatbots, traducción automática y asistentes de voz.
¿La PNL es aprendizaje automático o IA?
La PNL es una subconjunto de IA que usa técnicas de aprendizaje automático.
¿Cuál es la diferencia entre NLP y NLM?
- PNL (procesamiento del lenguaje natural) se centra en la comprensión del texto.
- NLM (modelo de lenguaje neuronal) es un modelo de aprendizaje profundo que predice la siguiente palabra de una secuencia.
Infraestructura de inteligencia artificial y aprendizaje automático en la nube
¿Qué proveedor de nube es mejor para la IA?
Colmena es la mejor opción para las cargas de trabajo de IA.
¿Qué certificación de IA en la nube es la mejor?
El Aprendizaje automático certificado por AWS: especialidad y Ingeniero de aprendizaje automático profesional de Google las certificaciones son muy valoradas.
¿Cuál es la mejor plataforma para aprender a usar IA?
Coursera, Udacity y fast.ai ofrecen excelentes programas de aprendizaje de IA.
¿Cómo entrenar modelos de IA en la nube?
Utilice plataformas en la nube como Compute with Hivenet, AWS SageMaker o Google AI Platform.
¿Cómo se puede utilizar la IA en la computación en la nube?
La IA se usa en escalado automático, análisis predictivo e impulsado por IA seguridad en la nube.d seguridad en la nube.

